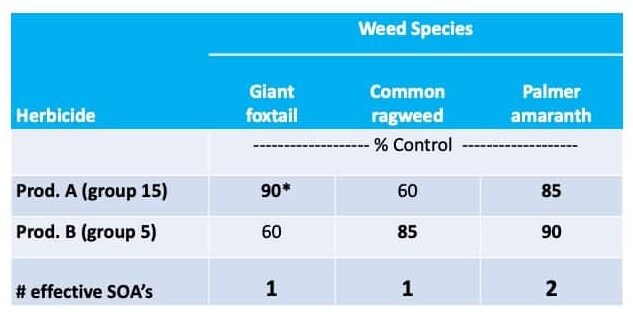
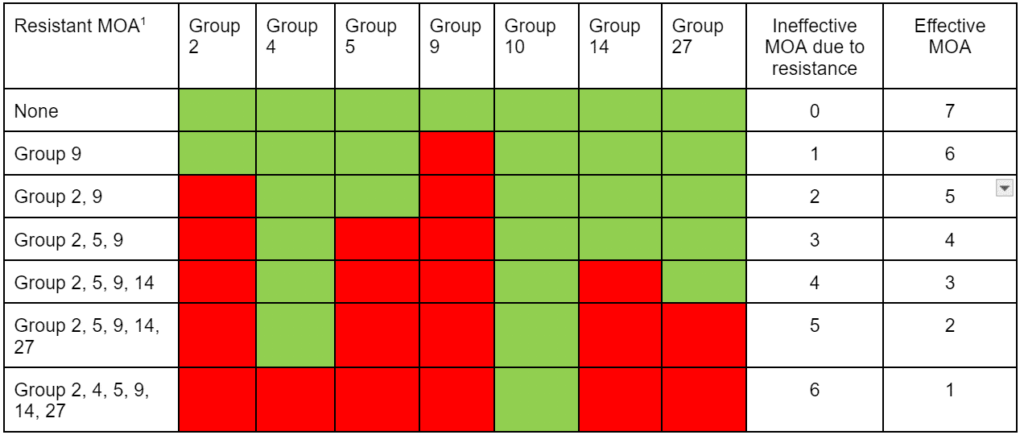
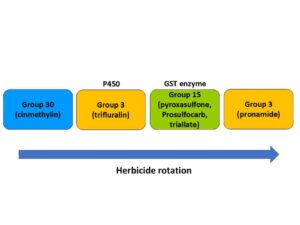
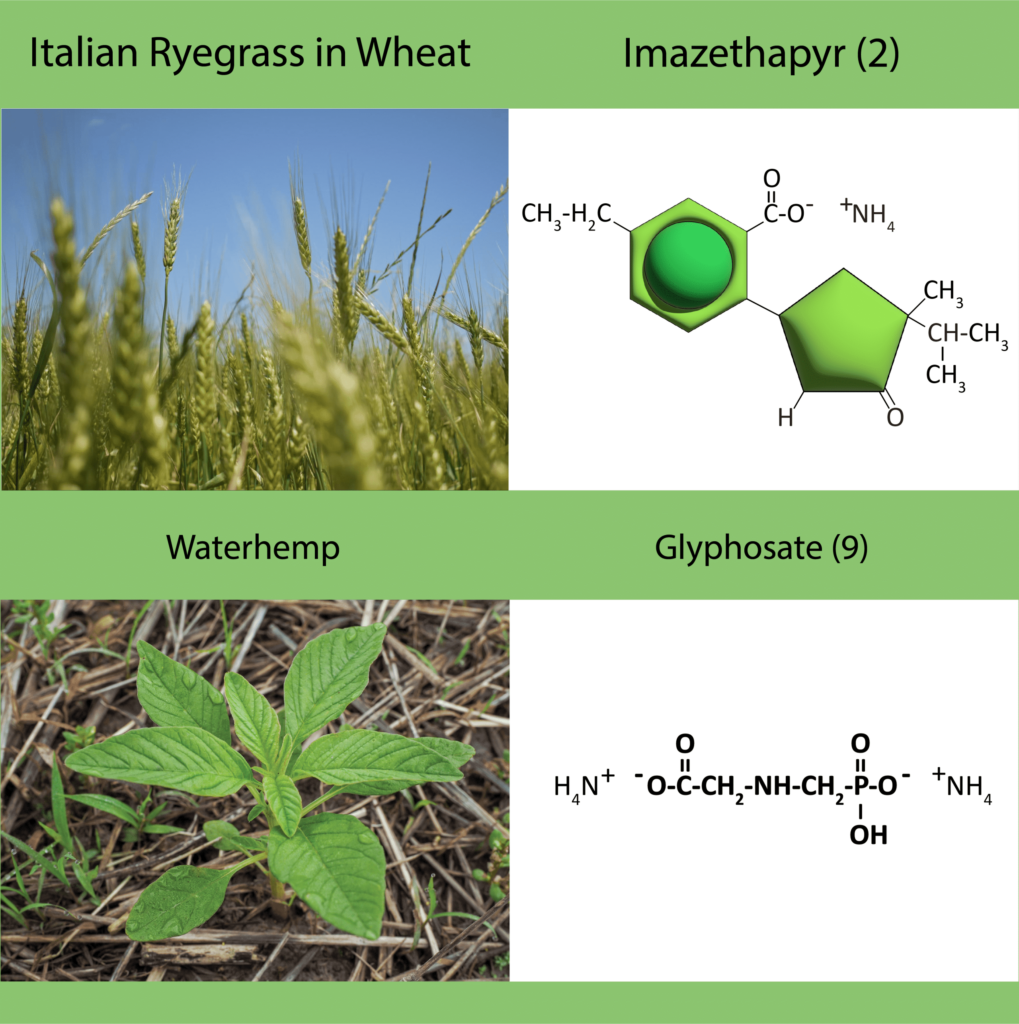
The National Agricultural Image Repository (NAIR) is a large-scale, multi-state effort to build and share weed and crop images, to train artificial intelligence (AI).
The repository will be open-access, meaning publicly available – the first step in faster and cheaper development of precision ag solutions. How? Simply put, open access to a resource like this repository makes it less likely for one group to monopolize the technology and increases the number of eyes working on a problem.
Ultimately, an open-access image repository can advance the development of “smart” precision technologies that can increase efficiency, lower costs, and improve the overall sustainability of farming practices, while also promoting open and collaborative research.
Get Big or Get Out
Datasets for AI need to be big.
The more images that machine learning algorithms are exposed to, the better they become at recognizing patterns and making predictions. For example, if an algorithm is trained on a small dataset of Palmer amaranth and cotton images, it may not be able to identify the difference between the weeds and the crop. But if a large dataset that contains diverse examples of these two species – such as different appearances, times of day, growth stages, and stress symptoms – is used for training, the algorithm is more likely to make accurate identifications. Important weeds are correctly identified for spraying, resulting in more reliable management and better yield.
Large image datasets provide a greater level of diversity, which is important for algorithms to learn to generalize and handle variations in the images. This is especially important in complex domains like agriculture and weed recognition, where variations in soil, weather, and other environmental factors can impact the growth of crops and the appearance of weeds.
How much data do we need to collect? The answer is… a lot!
Actually, that’s a trick question. It implies some static concrete number and end date. A better question is, “How can we continuously capture data?” Millions of images are needed, captured across different backdrops, conditions, growth stages, species, and an ever-growing list of situations. It’s a dynamic process that never ends since these datasets have to be inspected, updated, maintained, and cleaned. The image dataset has to be balanced and structural imperfections have to be identified and corrected. This means adding, removing, or reshaping.
Developing the dataset is like a large ball of clay that’s continuously massaged and shaped into a vase. Except, unlike a vase, weeds are constantly evolving to outsmart whatever management strategy humans use and will continue to do so, even with AI.
Why Ag Needs This Resource
Despite how important these large image datasets are, few exist for agriculture. Publicly available datasets in ag today are limited, developed mostly by small research groups and comprising only one to two thousand images and a couple of species.
“When more people can use the data, we all benefit. But when companies silo data behind closed doors, they stall progress for others and themselves. This has been the case for precision agriculture …“
There’s a good reason for this: Developing these datasets is not easy. It’s expensive, time consuming, and tedious to capture, label and update all the images needed. Often only massive companies like Microsoft and Google, and Google’s large video sharing platform, YouTube, can spend the hundreds of millions of dollars necessary to capture and label images. Many of these datasets have been made publicly available such as ImageNet (~128 million images)1, Microsoft’s COCO (328,000 images)2, and Google’s Open Images Dataset (~9 million images)3.
Publicly available datasets that democratize access to high-quality images allow for more widespread use and rapid development of “smart” technologies, software applications that use artificial intelligence and machine learning to perform tasks that would typically require human-level intelligence. When more people can use the data, we all benefit. But when companies silo data behind closed doors, they stall progress for others and themselves. This has been the case for precision agriculture where an absence of large datasets has become a major bottleneck for advancing artificial intelligence, particularly in weed recognition and precision management applications4.
The National Agricultural Image Repository tries to close this gap by providing a large and diverse dataset of images, allowing the algorithms to learn and improve their ability to detect and identify different types of weeds in a variety of conditions. Additionally, a large repository of images can be used to train and fine-tune algorithms to work in different regions, taking into account variations in local growing conditions, lighting, and weed types, crucial for allowing researchers, engineers, and developers to experiment and train robust algorithms.
The ag tech organization, Precision Sustainable Agriculture uses a host of methods to automate this large-scale image collection of weeds and crops, including using a machine called the BenchBot. For an indepth look at how the BenchBot does this – as well as more details on the image repository and the researchers working on it – see this video:
Stay tuned to GROW’s News Page for more articles on this technology and the work behind the National Agricultural Image Repository.
Text by Matthew Kutugata, Texas A&M University; Video by Claudio Rubione, GROW
Matthew Kutugata is a PhD student at Texas A&M University working with Precision Sustainable Agriculture (PSA) network on open-access resources for researchers, engineers, and the public to advance automatic weed recognition for farmers.
Citations
- Deng, Jia, et al. “Imagenet: A large-scale hierarchical image database.” 2009 IEEE conference on computer vision and pattern recognition. IEEE, 2009.
- Lin, Tsung-Yi, et al. “Microsoft coco: Common objects in context.” Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer International Publishing, 2014.
- Krasin, Ivan, et al. “Openimages: A public dataset for large-scale multi-label and multi-class image classification.” Dataset available from https://github. com/openimages 2.3 (2017): 18.
- Lu, Yuzhen, and Sierra Young. “A survey of public datasets for computer vision tasks in precision agriculture.” Computers and Electronics in Agriculture 178 (2020): 105760.